High-speed memory caches present in modern computer architectures favor data structures with good locality of reference, i.e. the property by which elements accessed in sequence are located in memory addresses close to each other. This is the rationale behind classes such as Boost.Container flat associative containers, that emulate the functionality of standard C++ node-based associative containers while storing the elements contiguously (and in order). This is an example of how binary search works in a boost::container::flat_set with elements 0 trough 30:
As searching narrows down towards the looked-for value, visited elements are progressively closer, so locality of reference is very good for the last part of the process, even if the first steps hop over large distances. All in all, the process is more cache-friendly than searching in a regular std::set (where elements are totally scattered throughout memory according to the allocator's whims) and resulting lookup times are consequently much better. But we can get even more cache-friendly than that.
Consider the structure of a classical red-black tree holding values 0 to 30:

and lay out the elements in a contiguous array following the tree's breadth-first (or level) order:
We can perform binary search on this level-order vector beginning with the first element (the root) and then jumping to either the "left" or "right" child as comparisons indicate:
The hopping pattern is somewhat different than with boost::container::flat_set: here, the first visited elements are close to each other and hops become increasingly longer. So, we get good locality of reference for the first part of the process, exactly the opposite than before. It could seem then that we are no better off with this new layout, but in fact we are. Let us have a look at the heat map of boost::container::flat_set:
This shows how frequently a given element is visited through an average binary search operation (brighter means "hotter", that is, accessed more). As every lookup begins at the mid element 15, this gets visited 100% of the times, then 7 and 23 have 50% visit frequency, etc. On the other hand, the analogous heat map for a level-order vector looks very different:
Now hotter elements are much closer: as cache management mechanisms try to keep hot areas longer in cache, we can then expect this layout to result in fewer cache misses overall. To summarize, we are improving locality of reference for hotter elements at the expense of colder areas of the array.
Let us measure this data structure in practice. I have written a protoype class template levelorder_vector<T> that stores its contents in level-order sequence and provides a member function for binary search:
const_iterator lower_bound(const T& x)const
{
size_type n=impl.size(),i=n,j=0;
while(j<n){
if(impl[j]<x){
j=2*j+2;
}
else{
i=j;
j=2*j+1;
}
}
return begin()+i;
}
A test program is provided that measures lower_bound execution times with a random sequence of values on containers std::set, boost::container::flat_set and levelorder_vector holding n = 10,000 to 3 million elements.
MSVC on Windows
Test built with Microsoft Visual Studio 2012 using default release mode settings and run on a Windows box with an Intel Core i5-2520M CPU @2.50GHz. Depicted values are microseconds/n, where n is the number of elements in the container.
 |
| lower_bound execution times / number of elements. |
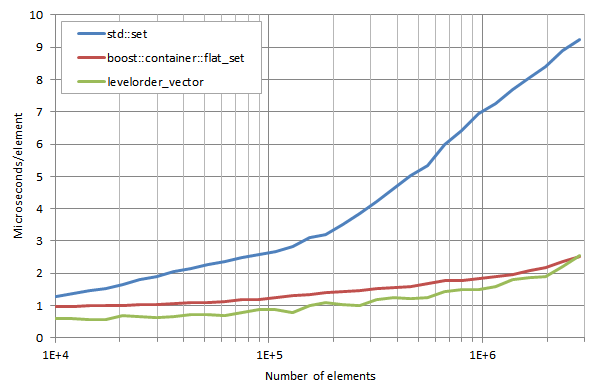
The theoretical lookup times for the three containers are O(log n), which should show as straight lines (horizontal scale is logarithmic), but increasing cache misses as n grows result in some upwards bending. As predicted, levelorder_vector performs better than boost::container::flat_set, with improvement factors ranging from 10% to 30%. Both containers are nevertheless much faster than std::set, and don't show much degradation until n ≃ 5·105 (~7·104 for std::set), which is a direct consequence of their superior cache friendliness.
GCC on Linux
The following people have kindly sent in test outputs for GCC on varius Linux platforms: Philippe Navaux, xckd, Manu Sánchez. Results are very similar, so we just show those corresponding to GCC 5.1 on a Intel Core i7-860 @ 2.80GHz with Linux kernel 4.0 from Debian:
 |
| lower_bound execution times / number of elements. |
Although levelorder_vector performs generally better than boost::container::flat_set, there is a strange phenomenon for which I don't have an explanation: improvement factors are around 40% for low values of n, but then decrease or even become negative as n aproaches 3·106. I'd be grateful if readers can offer interpretations of this.
Laurentiu Nicola has later submitted results with -march=native -O2 settings that differ significantly from the previous ones: GCC 5.1 on an Intel Core i7-2760QM CPU @ 2.40GHz (Linux distro undisclosed):
 |
| lower_bound execution times / number of elements. |
and GCC 5.1 on an Intel Celeron J1900 @ 1.99GHz:
 |
| lower_bound execution times / number of elements. |
-march=native seems to make a big difference: now levelorder_vector execution times are up to 25% (i7) and 40% (Celeron) lower than boost::container::flat_set when n approaches 3·106, but there is no significant gain for low values of n.
Clang on OS X
As provided by fortch: clang-500.2.79 in -std=c++0x mode on an Darwin 13.1.0 box with an Intel Core i7-3740QM CPU @ 2.70GHz.
 |
| lower_bound execution times / number of elements. |
The improvement of levelorder_vector with respect to boost::container::flat_set ranges from 10% to 20%.
Clang on Linux
Manu Sánchez has run the tests with Clang 3.6.1 on an Arch Linux 3.16 box with an Intel Core i7 4790k @4.5GHz. In the first case he has used the libstdc++-v3 standard library:
 |
| lower_bound execution times / number of elements. |
and then repeated with libc++:
 |
| lower_bound execution times / number of elements. |
Results are similar, with levelorder_vector execution speeds between 5% and 20% less than those of boost::container::flat_set. The very noticeable bumps on the graphs for these two containers when using libc++ are also present on the tests for Clang on OS X but do not appear if the standard library used is libstdc++-v3, which suggests that they might be due to some artifact related to libc++ memory allocator.
Laurentiu's results for Clang 3.6.1 with -march=native -O2 are similar to Manu's for an i7 CPU, whereas for an Intel Celeron J1900 @ 1.99GHz we have:
 |
| lower_bound execution times / number of elements. |
where levelorder_vector execution times are up to 35% lower than those of boost::container::flat_set.
Conclusions
Even though binary search on sorted vectors perform much better than node-base data structures, alternative contiguous layouts can achieve even more cache friendliness. We have shown a possibility based on arranging elements according to the breadth-first order of a binary tree holding the sorted sequence. This data structure can possibly perform worse, though, in other operations like insertion and deletion: we defer the study of this matter to a future entry.
I did a series of runs with g++ 4.{6789} and 5.1 -O3 on a Intel Core i7 860 @ 2.80GHz with Linux kernel 4.0 from Debian.
ReplyDeleteThe results can be found at http://charm.cs.illinois.edu/~phil/flat-btree/
It has been a bit since I have updated my c++ libraries, don't mind the 0x heh
ReplyDelete$ clang++ -v
Apple LLVM version 5.0 (clang-500.2.79) (based on LLVM 3.3svn)
Target: x86_64-apple-darwin13.1.0
Thread model: posix
$ sysctl -n machdep.cpu.brand_string
Intel(R) Core(TM) i7-3740QM CPU @ 2.70GHz
$ clang++ preorder_vector.cpp -std=c++11 -O3
output_clang_11.txt
$ clang++ preorder_vector.cpp -std=c++0x -O3
output_clang_0x.txt
Compiled with g++ 4.9.2 on Debian:
ReplyDeleteg++ -Ofast -Wall -Wextra -Werror -std=c++11 -o test levelorder_vector.cpp
The machine is an Intel(R) Core(TM) i7-4790T CPU @ 2.70GHz with 16GB RAM
Binary search:
std::set;boost::container::flat_set;levelorder_vector
10000;1.10664;0.774499;0.533323
12000;1.18407;0.789164;0.555826
14400;1.27004;0.799802;0.54171
17280;1.34722;0.81454;0.530249
20736;1.43015;0.830834;0.594138
24883;1.50467;0.842233;0.596146
29859;1.5937;0.868157;0.566802
35830;1.75523;0.874971;0.5836
42995;1.83315;0.881442;0.647675
51593;1.89309;0.919203;0.639589
61910;1.94726;0.936893;0.614695
74290;2.19871;0.948165;0.651943
89146;2.07348;0.979815;0.735306
106973;2.221;1.01198;0.712115
128365;2.3946;1.058;0.692551
154035;2.4648;1.07647;0.851917
184839;2.80888;1.1326;0.908473
221803;3.40933;1.171;0.866847
266159;3.28181;1.1883;0.843519
319386;4.14999;1.2394;0.951587
383258;4.23496;1.27694;1.00523
459904;4.8146;1.28158;1.1303
551879;5.07588;1.37047;1.06402
662249;5.67157;1.40763;1.13232
794693;6.52337;1.426;1.52635
953625;6.65547;1.37775;1.16741
1144343;7.1171;1.4559;1.24296
1373204;7.27995;1.47189;1.37101
1647837;8.07396;1.88349;1.58652
1977396;8.25508;1.75467;1.60646
2372866;8.49498;1.84866;1.80135
2847430;9.44917;2.07216;2.32611
Arch Linux 3.16 x86_64 Intel Core i7 4790k @4.5GHz 16GB RAM
ReplyDeleteGCC 5.1.0 -Wall -O3
std::set;boost::container::flat_set;levelorder_vector
10000;0.942178;0.649732;0.405604
12000;1.0163;0.661393;0.426551
14400;1.09829;0.673412;0.394561
17280;1.1708;0.68414;0.397729
20736;1.22752;0.696192;0.4574
24883;1.3168;0.70917;0.445425
29859;1.39845;0.719152;0.417932
35830;1.52342;0.732551;0.42978
42995;1.54287;0.74962;0.486241
51593;1.61979;0.758761;0.480406
61910;1.68448;0.776161;0.444349
74290;1.76935;0.809774;0.4911
89146;1.8292;0.832541;0.562394
106973;1.93549;0.865164;0.544891
128365;2.07622;0.891607;0.50524
154035;2.23172;0.924304;0.584387
184839;2.354;0.949735;0.678893
221803;2.66305;0.983547;0.641758
266159;2.94522;1.01617;0.635775
319386;3.49813;1.03448;0.771336
383258;3.94718;1.05866;0.847865
459904;4.07259;1.08642;0.929145
551879;4.16393;1.12095;0.917717
662249;5.14943;1.18708;0.857538
794693;5.98453;1.12341;0.848175
953625;6.41291;1.1347;0.830826
1144343;6.82237;1.15969;0.964873
1373204;7.1026;1.20294;1.03471
1647837;7.53148;1.21857;0.967981
1977396;8.0361;1.32692;1.0474
2372866;8.09712;1.41156;1.25784
2847430;8.53848;1.57566;1.74904
Clang 3.6.1 -Wall -O3 (gnu stdlibc++):
std::set;boost::container::flat_set;levelorder_vector
10000;0.993368;0.666357;0.630939
12000;1.07131;0.673273;0.635633
14400;1.13079;0.683148;0.643084
17280;1.213;0.693476;0.658646
20736;1.33367;0.705337;0.656572
24883;1.3532;0.7131;0.66242
29859;1.41948;0.720393;0.671182
35830;1.53041;0.734108;0.680093
42995;1.63618;0.744925;0.686951
51593;1.73344;0.757208;0.693145
61910;1.74293;0.775989;0.70711
74290;1.84671;0.818686;0.733187
89146;1.87382;0.839728;0.748626
106973;1.96041;0.859623;0.765006
128365;2.06532;0.901873;0.782139
154035;2.212;0.923579;0.79369
184839;2.36325;0.950378;0.804458
221803;2.63924;0.988126;0.831224
266159;3.43489;1.01654;0.838551
319386;3.42463;1.03174;0.847947
383258;3.94939;1.06131;0.86878
459904;4.35884;1.08742;0.875501
551879;4.77623;1.13165;0.891176
662249;5.46352;1.15979;0.901064
794693;6.04875;1.13259;0.914436
953625;6.60138;1.15176;0.925438
1144343;6.8115;1.16985;0.943092
1373204;7.16612;1.1905;0.958147
1647837;7.74718;1.22039;0.994402
1977396;8.00013;1.27861;1.03661
2372866;8.50959;1.41785;1.14635
2847430;9.1114;1.56756;1.26845
Clang 3.6.1 -Wall -O3 (LLVM libc++)
std::set;boost::container::flat_set;levelorder_vector
10000;1.20145;0.900542;0.858861
12000;1.21311;0.866906;0.82188
14400;1.24415;0.838789;0.79369
17280;1.46327;0.974148;0.935117
20736;1.47669;0.939277;0.888318
B24883;1.488;0.904221;0.848018
29859;1.53827;0.87751;0.821355
35830;1.78498;1.0131;0.949232
42995;1.72539;0.981349;0.913598
51593;1.76445;0.946652;0.886394
61910;1.7986;0.922748;0.864523
74290;2.04623;1.08704;0.994173
89146;2.15265;1.0754;0.961312
106973;2.14005;1.04145;0.934215
128365;2.25706;1.03695;0.9399
154035;3.4363;1.2096;1.06582
184839;3.12646;1.1852;1.0347
221803;3.5032;1.18023;1.00237
266159;3.7558;1.30898;1.12387
319386;3.51973;1.28644;1.0925
383258;3.62738;1.26987;1.06401
459904;4.03144;1.25995;1.07837
551879;4.82011;1.40394;1.18071
662249;4.98677;1.39467;1.13598
794693;5.61304;1.32911;1.10182
953625;6.1442;1.3126;1.07715
1144343;7.16668;1.44368;1.20948
1373204;6.92954;1.46197;1.23476
1647837;7.50992;1.41724;1.30037
1977396;7.88137;1.43963;1.17976
2372866;8.63361;1.69802;1.46556
2847430;8.58553;1.78567;1.52624
Interesting. GCC clearly wins the race, but note how Clang with stdlibc++ runs faster at the beginning, times get closer as the input grows, then libc++ wins at huge input sets.
One thing I've never understood about algorithms that attempt to optimize for cache effects is how you could expect these algorithms to work when they take place in virtual memory locations, which can be mapped to unpredictable physical memory locations. Since the cache works on physical memory, I would think that many of the desirable performance improvements in such algorithms would go away if contiguous virtual memory is mapped to non-contiguous physical memory.
ReplyDeleteBecause virtual memory is a hardware feature. So the prefetching, caching, etc, works in virtual address space, not physical address space.
DeleteAre threaded comments enabled Joaquin? I'm not sure how I can directly answer to Sudsy. Also, it's possible to edit comments?
ReplyDelete@Sudsy typical L1 caches have lines 64 bytes wide. On most OSs VM pages are about 4KB. These are completely different beasts. Note the scale, VM locality does not affect cache since VM works in units orders of magnitude bigger.
Are threaded comments enabled Joaquin?
DeleteI've just done so.
Also, it's possible to edit comments?
Seems like Blogger does not have that option. Do you think otherwise?
This comment has been removed by the author.
Delete> Seems like Blogger does not have that option. Do you think otherwise?
DeleteNope. Seems the only way is to delete and rewrite, as I'm doing for this one...
Someone else started looking into memory layouts for binary search not too long ago.
ReplyDeleteThis comes at the cost of decreased in-order traversal. The nice thing about flat_map is that it is ordered such that in-order traversal moves sequentially in memory. Not only cache friendly, but prefetchers love that.
ReplyDeleteThat being said, maybe you don't need to do that often and you spend more time searching, but if that's the case, one should consider if ordering is needed at all, and if not, consider a hash table instead.
Hi Chris, you're right traversing this structure is bound to be slower than boost::container::flat_set, and I'd like to study this in detail in a future entry, if time permits. As for hash tables, they're definitely faster for lookup (check for instance this entry, where lookup times for MSVC are around 2-3x faster than shown here), but then you lose the ability to traverse the elements in ordered fashion. At the end of the day, data structures are about balancing trade-offs among the different usage scenarios one is interested in.
DeleteI don't know if my previous comment made it, but here are my results: https://gist.github.com/GrayShade/807e1efd4a42a47e1506 .
ReplyDeleteThank you for the submission, just included in the article. I don't know what happened to your previous comment, it does't appear anywhere on my control panel (spam, waiting moderation, etc.)
Delete"less cache misses" -> "fewer cache misses"
ReplyDeleteAnd now we need to combine the two algorithms: levelorder_vector to start the search then switch to Ye Olde plain vector when the search radius falls below the cache size (or something like that, to be profiled).
"less cache misses" -> "fewer cache misses"
DeleteCorrected, thank you.
And now we need to combine the two algorithms [...]
Yes, that would make for an interesting variation, I might try if time permits.
Wow, a great Interview question for senior developers ... Thanks JP
ReplyDeleteHi. I am writing a paper on vectorization (SIMD) of various algorithms to search in a sorted array. I like this approach and I would like to add it to the set of algorithm I am testing. Is this algorithm described in any journal publication? Fab
ReplyDeleteHi Fabio,
DeleteYes, this arrangement is called "Eytzinger layout" in the academic literature. You can, for instance, follow the link below for more info and additional references:
https://arxiv.org/ftp/arxiv/papers/1509/1509.05053.pdf
Thanks for a great blogpost!
ReplyDeleteI've implemented this layout as a generic STL-like associative container:
https://github.com/mikekazakov/eytzinger/
https://kazakov.life/2017/03/06/cache-friendly-associative-container/