- Introduction
- State of the art
- Design principles
- Data structure
- Algorithms
- Visitation API
- Benchmarks
- Conclusions and next steps
Starting in Boost 1.83, Boost.Unordered provides
boost::concurrent_flat_map, an associative container suitable for high-load parallel scenarios.
boost::concurrent_flat_map leverages much of the work done for
boost::unordered_flat_map,
but also introduces innovations, particularly in the areas of low-contention
operation and API design, that we find worth discussing.
The space of C++ concurrent hashmaps spans a diversity of competing techniques, from traditional ones such as lock-based structures or sharding, to very specialized approaches relying on CAS instructions, hazard pointers, Read-Copy-Update (RCU), etc. We list some prominent examples:
tbb::concurrent_hash_mapuses closed addressing combined with bucket-level read-write locking. The bucket array is split in a number of segments to allow for incremental rehashing without locking the entire table. Concurrent insertion, lookup and erasure are supported, but iterators are not thread safe. Locked access to elements is done via so-called accessors.tbb::concurrent_unordered_mapalso uses closed addressing, but buckets are organized into lock-free split-ordered lists. Concurrent insertion, lookup, and traversal are supported, whereas erasure is not thread safe. Element access via iterators is not protected against data races.- Sharding consists in dividing the hashmap into a fixed number N of submaps indexed
by hash (typically, the element x goes into the submap with index hash(x) mod N).
Sharding is extremely easy to implement starting from a non-concurrent hashmap and provides
incremental rehashing, but the degree of concurrency is limited by N.
As an example,
gtl::parallel_flat_hash_mapuses sharding with submaps essentially derived fromabsl::flat_hash_map, and inherits the excellent performance of this base container. libcuckoo::cuckoohash_mapadds efficient thread safety to classical cuckoo hashing by means of a number of carefully engineered techniques including fine-grained locking of slot groups or "strips" (of size 4 by default), optimistic insertion and data prefetching.- Meta's
folly::ConcurrentHashMapcombines closed addressing, sharding and hazard pointers to elements to achieve lock-free lookup (modifying operations such as insertion and erasure lock the affected shard). Iterators, which internally hold a hazard pointer to the element, can be validly dereferenced even after the element has been erased from the map; access, on the other hand, is constant and elements are basically treated as immutable. folly::AtomicHashMapis a very specialized hashmap that imposes severe usage restrictions in exchange for very high time and space performance. Keys must be trivially copyable and 32 or 64 bits in size so that they can be handled internally by means of atomic instructions; also, some key values must be reserved to mark empty slots, tombstones and locked elements, so that no extra memory is required for bookkeeping information and locks. The internal data structure is based on open addressing with linear probing. Non-modifying operations are lock-free. Rehashing is not provided: instead, extra bucket arrays are appended when the map becomes full, the expectation being that the user provide the estimated final size at construction time to avoid this rather inefficient growth mechanism. Element access is not protected against data races.- On a more experimental/academic note, we can mention initiatives such as Junction, Folklore and DRAMHiT. In general, these do not provide industry-grade container implementations but explore interesting ideas that could eventually be adopted by mainstream libraries, such as RCU-based data structures, lock-free algorithms relying on CAS and/or transactional memory, parallel rehashing and operation batching.
Unlike non-concurrent C++ containers, where the STL acts as a sort of
reference interface, concurrent hashmaps in the market
differ wildly in terms of requirements, API and provided functionality. When
designing boost::concurrent_flat_map, we have aimed for a general-purpose
container
- with no special restrictions on key and mapped types,
- providing full thread safety without external synchronization mechanisms,
- and disrupting as little as possible the conceptual and operational model of "traditional" containers.
These principles rule out some scenarios such as requiring that keys be of an integral type or putting an extra burden on the user in terms of access synchronization or active garbage collection. They also inform concrete design decisions:
boost::concurrent_flat_map<Key, T, Hash, Pred, Allocator>must be a valid instantiation in all practical cases whereboost::unordered_flat_map<Key, T, Hash, Pred, Allocator>is.- Thread-safe value semantics are provided (including copy construction, assignment, swap, etc.)
- All member functions in
boost::unordered_flat_mapare provided byboost::concurrent_flat_mapexcept if there's a fundamental reason why they can't work safely or efficiently in a concurrent setting.
The last guideline has the most impact on API design. In particular, we have decided not to provide iterators, either blocking or not: if not-blocking, they're unsafe, and if blocking they increase contention when not properly used, and can very easily lead to deadlocks:
// Thread 1
map_type::iterator it1=map.find(x1), it2=map.find(x2);
// Thread 2
map_type::iterator it2=map.find(x2), it1=map.find(x1);In place of iterators, boost::concurrent_flat_map offers an access API
based on internal visitation, as described in a later section.
boost::concurrent_flat_map uses the same
open-addressing layout
as boost::unordered_flat_map, where the bucket array is split into
2n groups of N = 15 slots and each group has an associated
16-byte metadata word for SIMD-based reduced-hash matching and insertion overflow
control.
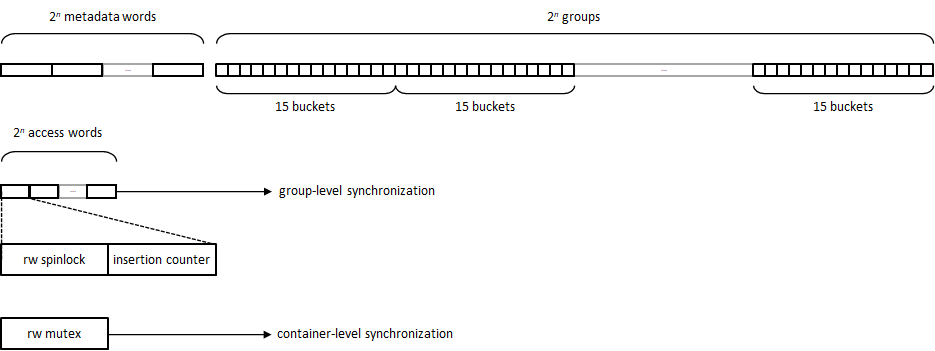
On top of this layout, two synchronization levels are added:
- Container level: A read-write mutex is used to control access from any operation to the
container. This access is always requested in read mode (i.e. shared) except for operations
that require that the whole bucket array be replaced, like rehashing, swapping,
assignment, etc. This means that, in practice, this level of synchronization does
not cause any contention at all, even for modifying operations like insertion and
erasure. To reduce cache coherence traffic, the mutex is implemented as an array
of read-write spinlocks occupying separate cache lines, and each thread is
assigned one spinlock in a round-robin fashion at
thread_localconstruction time: read/shared access does only involve the assigned spinlock, whereas write/exclusive access, which is comparatively much rarer, requires that all spinlocks be locked. - Group level: Each group has a dedicated read-write spinlock to control access to its slots, plus an atomic insertion counter used for transactional optimistic insertion as described below.
The core algorithms of boost::concurrent_flat_map are variations of those of
boost::unordered_flat_map with minimal changes to prevent data races while keeping
group-level contention to a minimum.
In the following diagrams, white boxes represent lock-free steps, while gray boxes are executed within the scope of a group lock. Metadata is handled atomically both in locked and lock-free scenarios.

Most steps of the lookup algorithm (hash calculation, probing, element pre-checking via SIMD matching with the value's reduced hash) are lock-free and do not synchronize with any operation on the metadata. When SIMD matching detects a potential candidate, double-checking for slot occupancy and the actual comparison with the element are done within the group lock; note that the occupancy double check is necessary precisely because SIMD matching is lock-free and the status of the identified slot may have changed before group locking.

The main challenge of any concurrent insertion algorithm is to prevent an element x from being inserted twice by different threads running at the same time. As open-addressing probing starts at a position p0 univocally determined by the hash value of x, a naïve (and flawed) approach is to lock p0 for the entire duration of the insertion procedure: this leads to deadlocking if the probing sequences of two different elements intersect.
We have implemented the following transactional optimistic insertion algorithm: At the beginning of insertion, the value of the insertion counter for the group at position p0 is saved locally and insertion proceeds normally, first checking that an element equivalent to x does not exist and then looking for available slots starting at p0 and locking only one group of the probing sequence at a time; when an available slot is found, the associated metadata is updated, the insertion counter at p0 is incremented, and:
- If no other thread got in the way (i.e. if the pre-increment value of the counter coincides with the local value stored at the beginning), then the transaction is successful and insertion can be finished by storing the element into the slot before releasing the group lock.
- Otherwise, metadata changes are rolled back and the entire insertion process is started over.
Our measurements indicate that, even under adversarial situations, the ratio of start-overs to successful insertions ranges in the parts per million.
From an operational point of view, container iterators serve two main purposes: combining lookup/insertion with further access to the relevant element:
auto it = m.find(k);
if (it != m.end()) {
it->second = 0;
}and container traversal:
// iterators used internally by range-for
for(auto& x: m) {
x.second = 0;
}Having decided that boost::concurrent_flat_map not rely on iterators
due to their inherent concurrency problems, a design alternative is to move element
access into the container operations themselves, where it can be done in a
thread-safe manner. This is just a form of the familiar visitation pattern:
m.visit(k, [](auto& x) {
x.second = 0;
});
m.visit_all([](auto& x) {
x.second = 0;
});boost::concurrent_flat_map provides visitation-enabled variations
of classical map operations wherever it makes sense:
visit,cvisit(in place offind)visit_all,cvisit_all(as a substitute of container traversal)emplace_or_visit,emplace_or_cvisitinsert_or_visit,insert_or_cvisittry_emplace_or_visit,try_emplace_or_cvisit
cvisit stands for constant visitation, that is, the visitation function
is granted read-only access to the element, which has less contention than
write access.
Traversal functions [c]visit_all and erase_if have also parallel versions:
m.visit_all(std::execution::par, [](auto& x) {
x.second = 0;
});We've tested boost::concurrent_flat_map against
tbb::concurrent_hash_map
and gtl::parallel_flat_hash_map
for the following synthetic scenario:
T threads concurrently perform N operations update, successful lookup
and unsuccessful lookup, randomly chosen with probabilities 10%, 45% and 45%, respectively,
on a concurrent map of (int, int) pairs.
The keys used by all operations are also random, where update and successful lookup follow a
Zipf distribution over [1, N/10]
with skew exponent s, and unsuccessful lookup follows a Zip distribution
with the same skew s over an interval not overlapping with the former.
We provide the full benchmark code and results for different 64- and 32-bit architectures in a dedicated repository; here, we just show as an example the plots for Visual Studio 2022 in x64 mode on an AMD Ryzen 5 3600 6-Core @ 3.60 GHz without hyperthreading and 64 GB of RAM.
 |
 |
 |
|---|---|---|
| 500k updates, 4.5M lookups skew=0.01 |
500k updates, 4.5M lookups skew=0.5 |
500k updates, 4.5M lookups skew=0.99 |
 |
 |
 |
|---|---|---|
| 5M updates, 45M lookups skew=0.01 |
5M updates, 45M lookups skew=0.5 |
5M updates, 45M lookups skew=0.99 |
Note that, for the scenario with 500k updates, boost::concurrent_flat_map
continues to improve after the number of threads exceed the number of cores (6),
a phenomenon for which we don't have a readily explanation —we could hypothesize
that execution is limited by memory latency, but the behavior does
not reproduce in the scenario with 5M updates, where the cache miss ratio is
necessarily higher. Note also that gtl::parallel_flat_hash_map performs
comparatively worse for high-skew scenarios where the load is concentrated on
a very small number of keys: this may be due to gtl::parallel_flat_hash_map
having a much coarser lock granularity (256 shards in the configuration used) than
the other two containers.
In general, results are very dependent on the particular CPU and memory system used; you are welcome to try out the benchmark in your architecture of interest and report back.
boost::concurrent_flat_map is a new, general-purpose concurrent hashmap that
leverages the very performant open-addressing techniques of boost::unordered_flat_map
and provides a fully thread-safe, iterator-free API we hope future users will
find flexible and convenient.
We are considering a number of new functionalities for upcoming releases:
- As
boost::concurrent_flat_mapandboost::unordered_flat_mapbasically share the same data layout, it's possible to efficiently implement move construction from one to another by simply transferring the internal structure. There are scenarios where this feature can lead to more performant execution, like, for instance, multithreaded population of aboost::concurrent_flat_mapfollowed by single- or multithreaded read-only lookup on aboost::unordered_flat_mapmove-constructed from the former. - DRAMHiT shows that pipelining/batching several map operations on the same thread in combination with heavy memory prefetching can reduce or eliminate waiting CPU cycles. We have conducted some preliminary experiments using this idea for a feature we dubbed bulk lookup (providing an array of keys to look for at once), with promising results.
We're launching this new container with trepidation: we cannot possibly
try the vast array of different CPU architectures and scenarios
where concurrent hashmaps are used, and we don't have yet field data on
the suitability of the novel API we're proposing for
boost::concurrent_flat_map. For these reasons, your feedback
and proposals for improvement are most welcome.
This map looks very promising! If a "visit" function does not find an element, it throws out_of_range exeption?
ReplyDeleteIf a visit operation does not find the element, it returns 0 (and 1 otherwise).
ReplyDelete